AI-Lab2 — Supervised Learning
By Dano Roost, Jennifer Schürch & Yves Lütjens
04.05.2020
The aim of this lab is to train a binary classifier that labels text with hate speech or not hate speech. The baseline already achieves an accuracy of 90% but with a very unbalanced set, meaning 11% are hate speeches and the rest are non-hate speeches.
Approach
We tried different approaches to achieve the highest possible score and compared them against each other. Furthermore, we created a balanced dataset that has a 50-50 ratio of hate speeches versus non-hate speeches, thus giving a less biased view how well the classifiers perform. In total we implemented four different approaches:
- Two different fully connected Neural Network with different layer sizes and TFIDF-Vectors
- A Recurrent Neural Network (RNN) with pretrained word embeddings (GloVe)
- A Convolutional Neural Network (CNN) with pretrained word embeddings (GloVe)
The two fully connected NNs are implemented in Keras, the RNN and the CNN are implemented in PyTorch. These two networks use TorchText for pre-processing and word embedding/padding/etc.
Evaluation
All evaluations are performed on a separate test set. As seen in the following plots, using a balanced or unbalanced dataset heavily impacts the performance of the classifiers. The baseline as well as the fully connected 2 NN struggle with the unbalanced dataset in class 1. The RNN and the CNN on the other hand, are performing better but still perform quite far from perfect, at least in the unbalanced case.
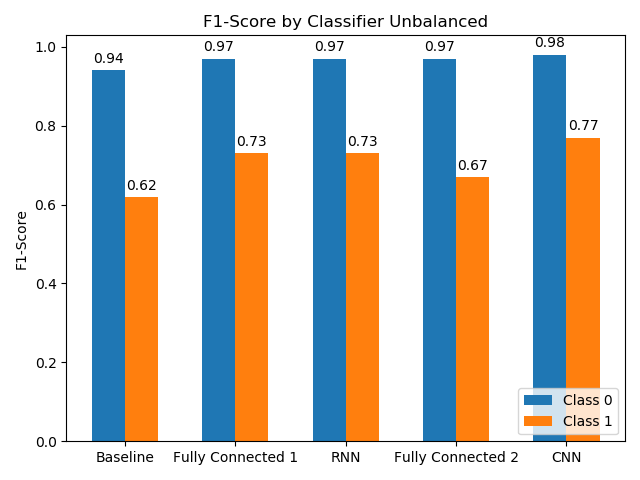
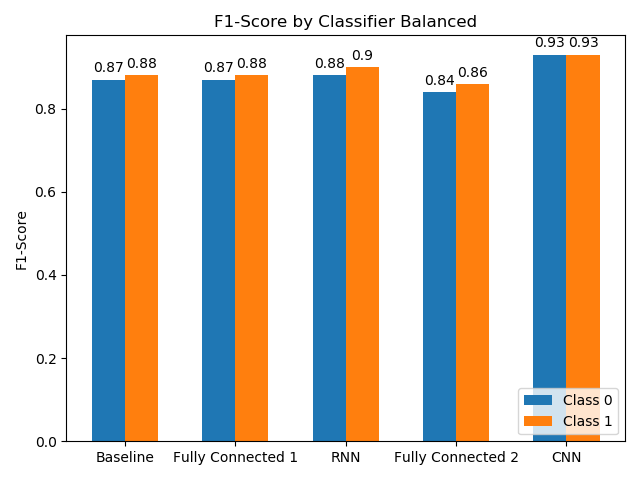
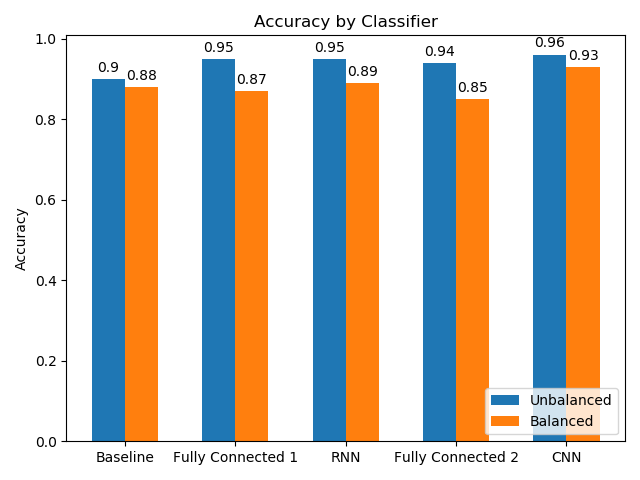
Analysing the accuracy of the classifiers as seen in the following plot, the CNN performs the best, followed by the RNN. Surprisingly the baseline algorithm loses the least accuracy if comparing the balanced dataset with the unbalanced one, but all proposed solutions outrun the baseline in terms of accuracy. This leads to the conclusion that a CNN is best suited for the task at hand, but all of the applied techniques perform well for the given problem statement.
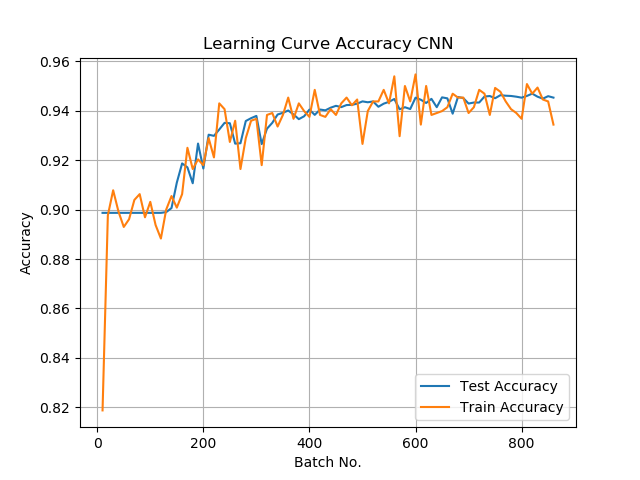
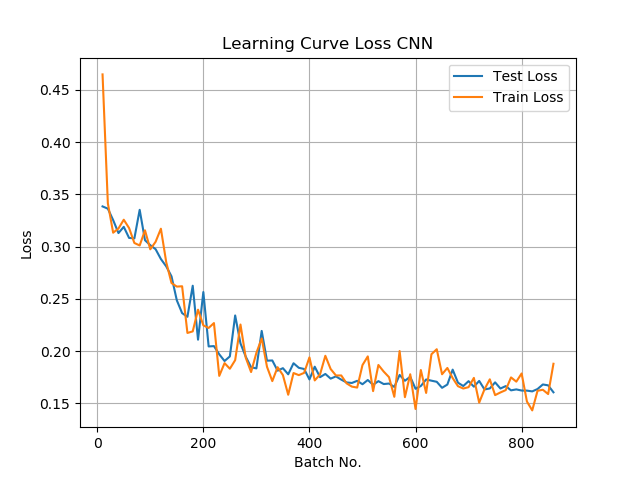
Learning Curve CNN
To verify our CNN approach we analysed the learning curves of the accuracy and the loss function from the CNN. We conclude, that the loss curve settles after 800 batches, which means that the amount of training data is right. Furthermore we can say that the Model doesn’t over- or underfit as the train and test data curves are very similar.
Console Application
Additionally, we made a small console application, which returns the hate speech score and up to three words hate words from a given sentence. There is a pool of words, which strongly correlate with hate speech for example: faggot, ass, stupid, idiot, shit, gay, hell, screw etc. When these words are present in a given sentence, the hate speech score gets automatically boosted regardless of the context used in the sentence. Below is an example with the word "gay" and "stupid":
| Example | Score | Example | Score |
|---|---|---|---|
| gay | 0.34 | stupid | 0.86 |
| You are gay | 0.55 | You are stupid | 0.94 |
| I am gay | 0.55 | I am stupid | 0.94 |
| The word gay had originally a different meaning | 0.54 | I have never felt so stupid in my life | 0.90 |